この記事は最終更新日から1年以上が経過しています。情報が古くなっている可能性があります。
Windows 上の Python (Python3) で open() 関数を使ったときに出る UnicodeDecodeError (ex: UnicodeDecodeError: 'cp932' codec can't decode byte 0x** in position **: illegal multibyte sequence) といえば、Python が標準でファイルの文字エンコーディングをかの悪名高い Shift-JIS (CP932) として読み込んでしまうことが原因であることはそれなりに知られているかと思います。
このエラー、自分で書いたコードなら全ての open() 関数の引数に encoding='utf-8' を追加してあげれば回避できますが、使おうとしたライブラリからそのエラーが出る場合はこちら側から制御できないので絶望するしかありません。
英語圏だと指定しなくても動いてしまう事が大半なこともあってか、一部のライブラリでは open() 関数を encoding 引数を付けずに実行するコードになっている事があります。
この記事 いわく、環境変数に PYTHONUTF8=1 を登録すればデフォルトで UTF-8 を使ってくれるようになるそうですが、さすがにユーザーに環境変数いじれとは言いづらいです。
さらに、そもそも Python コード側から open() 関数を UTF-8 で開くように強制することはできません。
python -X utf-8 (ファイル名) のように -X utf-8 をつけて実行しても UTF-8 モードになるようですが、こちらもプログラム側では UTF-8 モードにできないので却下。
最悪ユーザーに向けて「このスクリプトを実行するときは必ず UTF-8 モードで実行すること」と書いておくことも可能でしょうけど、煩わしいしできるだけ避けたいところです。
こちらの記事 では散々試したけど結局変えられなかったそうで、ただただつらい。
どうしてこうなった
open() 関数の encoding はオプション引数になっているので、何も指定しなかった場合、「macOS・Linux など標準でシステムロケールが UTF-8 になっている OS であれば」読み込むファイルが UTF-8 であると仮定して読み込まれます。
Linux だと以前は EUC-JP や Shift-JIS の文字エンコーディングが使われることもあったようですが、現在はほとんどの環境で UTF-8 に統一されています。
ところが Windows 環境のコマンドラインでは、文字エンコーディング(コード)がデフォルトで Shift-JIS こと CP932 になっています[1]ちなみに英語圏では Windows-1252 こと CP1252。
UTF-8 のテキストを Shift-JIS で読み込めるわけもなく、encoding 引数に 'utf-8' と明示的に文字コードを指定してあげない限り、文字のデコードに失敗して UnicodeDecodeError を出して落ちてしまいます。軽く死んでほしい。
Python のドキュメントいわく、正確には locale.getpreferredencoding() の返す値を使うようになっているらしいです(encoding 引数をオプションにするのならどのプラットフォームでもデフォルト UTF-8 で読み込んでおくれ…)。
つまりは open() 関数に食わせるファイルが UTF-8 であるという前提でプログラムを組むなら、Windows 環境でも UTF-8 で読み込まれるように encoding='utf-8' を必ず追加しないといけません。
…が、英語圏だと ASCII 範囲の文字しか使わなかったりで UTF-8 と Windows-1252 で文字コードが別でもさほどエラー吐かなかったりするからなのか、それをやり忘れているライブラリの多いこと多いこと…😡😡
逆に読み込むファイルの文字コードを Shift-JIS にすれば一応解消はしますが、絵文字使えないし逆に他の OS で読み込めなくなってしまうので、できるだけ避けたいところです。
とはいえ、ライブラリ自体のコードを直接いじるのも気が引けます…。
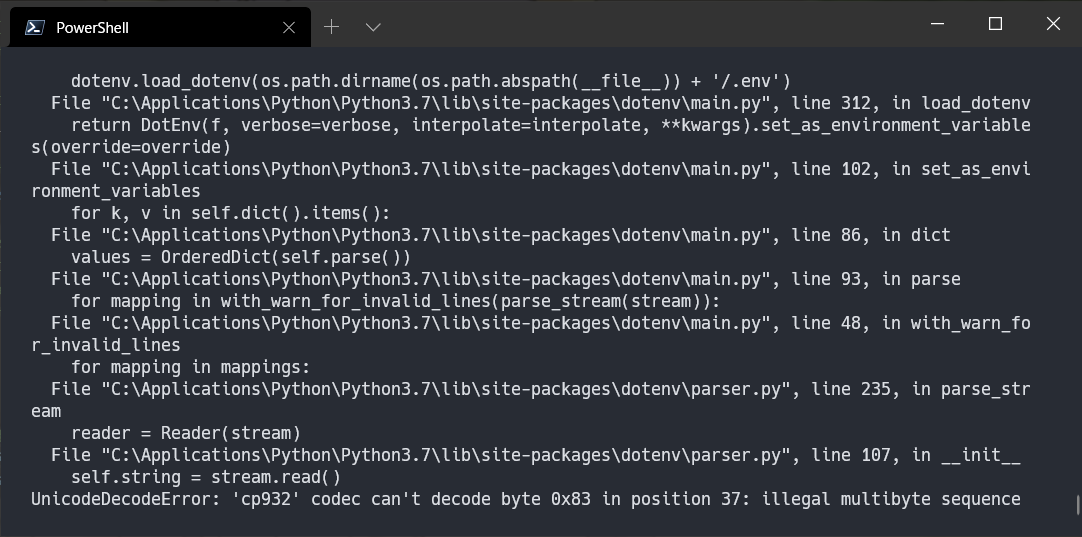
今回実際に詰まったのは、python-dotenv ライブラリの load_dotenv() 関数に日本語のコメントを書いた UTF-8 の .env ファイルを読み込ませると、python-dotenv 側が CP932 で読み込もうとしてしまい UnicodeDecodeError になる問題でした。
これに関しては こちら のプルリクがマージされた事で、 load_dotenv() 関数に encoding='utf-8' を指定してあげれば UTF-8 で読み込めるようになりました。もっとも、.env に日本語のコメントを書かなければ(=ASCII範囲で収まっていれば)問題になることはありません。
強引にハックする
で、お待ちかねの黒魔術強引にハックする方法がこちらになります。
ネットの海を漁ってたらたまたま見つけた StackOverflow の質問 に対する こちらの回答 が大変参考になりました。
# Windows 環境向けのハック
# 参考: https://stackoverflow.com/questions/31469707/changing-the-locale-preferred-encoding-in-python-3-in-windows
import os
if os.name == 'nt':
import _locale
_locale._getdefaultlocale_backup = _locale._getdefaultlocale
_locale._getdefaultlocale = (lambda *args: (_locale._getdefaultlocale_backup()[0], 'UTF-8'))以上のコードを、UnicodeDecodeError が発生するライブラリを呼び出すコードよりも前にコピペします。
するとこのコード以降の処理のデフォルト文字コードが UTF-8 に固定されるため、どのような場合でも 'cp932' codec can't decode byte … というエラーが出なくなり、ファイルを正しく UTF-8 で読み込めるようになるはずです。
このハックより後に記述されたコードで直接、または間接的に呼び出される locale.getdefaultlocale() 関数の挙動そのものを変更するもので、事実上 Python を UTF-8 モードで起動しているのとほぼ同じ状態になります。
if os.name == 'nt': では OS が Windows かどうかを判定しています。os モジュールを利用するため、import os も必須です(それより前のコードで import している場合は不要)。
こういう無理やり書き換える系のコードは モンキーパッチ と呼ばれます。
二重実行されるとそれはそれでエラーが出る気がするので、エントリーポイントで読んで他の処理で呼ばれないようにしたり、クラスの初期化時だけ実行するだとかの対策が必要かもしれません。
Python の UTF-8 モードの実装経緯は こちら に詳しく載っていました。後方互換性…しんどい…
動作原理
私も完全に理解できていませんが、動作原理は以下のようになっていると思われます。
Python の標準ライブラリである locale(Python製)が内部的に利用する、_locale というネイティブの隠し標準ライブラリ(C言語製)が存在します。
そこで、_locale 内の関数のうち、 _getdefaultlocale() 関数(標準のロケール設定を取得しようと試み、結果をタプル (language code, encoding) の形式で返す)を上書きします。
具体的には、あらかじめ _getdefaultlocale() 関数をバックアップした、ネイティブの _getdefaultlocale_backup() 関数が返す国コードと、UTF-8 に固定した文字コードのタプルで返す関数を代入し、無理やり上書きします。
こうしてその後のコードで実行される locale.getdefaultlocale() 関数の文字コードの返り値を無理やり UTF-8 に固定することで実現しているものと思われます。超荒業…。
先ほど述べた通り、 open() 関数の内部では encoding 引数がなかった場合は locale.getpreferredencoding() の返す値を使うようになっています。
そして、locale.getpreferredencoding() は OS が Windows の場合、_bootlocale という隠し標準ライブラリ内の _bootlocale.getpreferredencoding() に処理を投げます。
さらに _bootlocale.getpreferredencoding() は OS が Windows の場合、先ほど上書きした locale._getdefaultlocale() が返すタプルの 1 番目の値(文字コード)を利用するようになっているため、巡り巡って open() 関数に encoding 引数を指定しなかった場合、Windows でもデフォルトで UTF-8 で開くようにできる、といった具合みたいです。
かなり無理やりな方法ではありますが、macOS や Linux 上の Python の locale.getdefaultlocale() が返す文字コードは基本的に 'UTF-8' なので、さほど問題にはならないんじゃないかなーと思っています。
このハック(モンキーパッチ)を実行するファイルの一番上に追記するという手間は残りますが、この方法なら UnicodeDecodeError 地獄をなんとかできそうです。
副作用も少なく比較的安全なハックだとは思いますが、とはいえかなり強引な方法です。
もしお使いのライブラリで文字の encoding を指定する引数があるのであれば、それを指定するのが無難だと思います。このハックはあくまで最終手段です…。
Python のコードを読んでいて、もしや sys.flags.utf8_mode を True に変更すればプログラムから UTF-8 mode で実行できるのでは?と思ったりもしました。
…がそううまく行くはずもなく、sys ライブラリが C 言語で実装されているからか、プロパティ自体 readonly 扱いになっていて、Python 側から変更することはできませんでした。残念…。
コメント
助かりました!
windows のシステムロケール設定を「ワールドワイド言語サポートでUnicode UTF-8を使用」に変更してしのいでいましたが、それだと動かなくなってしまうソフトがあって困っていたところでした。
こちらこそ役に立ったようで何よりです。
もっとも、ライブラリ側でファイルの encoding を指定する引数があるのであれば、できるだけこのハックは使わないほうがよいとは思います。あくまで最終手段です…。